[本站讯]近日,软件学院16项研究成果被AAAI人工智能会议(AAAI Conference on Artificial Intelligence)录用,其中,时间序列可靠建模、数智化牙科、多模态大模型三项工作入选大会Oral。
成果一:ReCast: Reliability-aware Codebook-assisted Lightweight Time Series Forecasting (oral)。
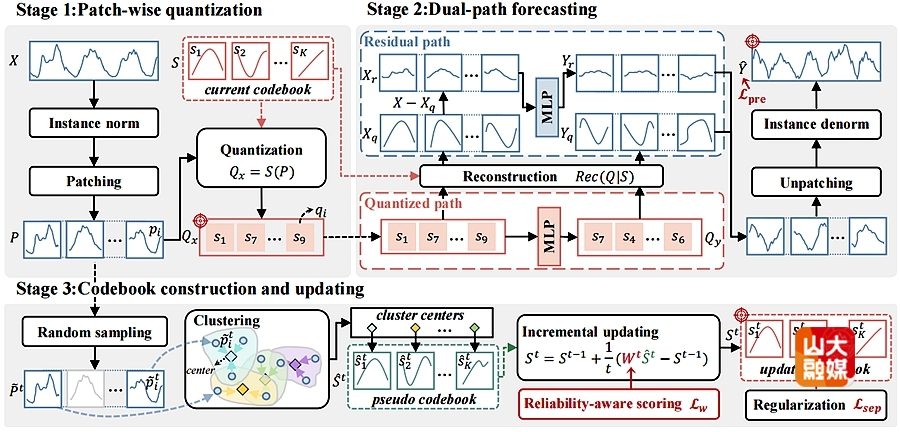
时间序列预测在众多领域应用中具有关键作用。现有方法通常依赖于将序列全局分解为趋势项、季节项和残差项,但面对以局部性、复杂性和高度动态性为主导的真实世界的序列时,效果并不理想。并且此类方法的高模型复杂度也限制了其在实时或资源受限环境中的应用。为此,本研究提出了一种新颖的基于可靠性感知码本的时序预测框架(ReCast),通过挖掘在历史数据中重复出现的局部形态,实现轻量化且鲁棒的预测。ReCast利用可学习码本通过分片量化(quantization)将局部模式编码为离散嵌入,从而紧凑地捕捉稳定的规律性结构。为弥补量化过程中未保留的残差变化,ReCast采用一种双路径架构:量化路径用于高效建模规律结构,残差路径则负责重构不规则残差。该框架的核心创新在于可靠性感知的码本更新策略,通过加权修正实现码本逐步优化。修正权重取自分布鲁棒优化(DRO)对多视角可靠性因子的融合,确保模型能适应非平稳性并抑制分布漂移的影响。软件学院博士后马翔为该篇文章的第一作者,学院教授李雪梅为通讯作者,学院教授崔立真对此研究给予了重要的指导和帮助。
成果二:DentalGS: Pose-Free 3D Gaussian Splatting from Five Intraoral Images for Novel View Synthesis(oral)。
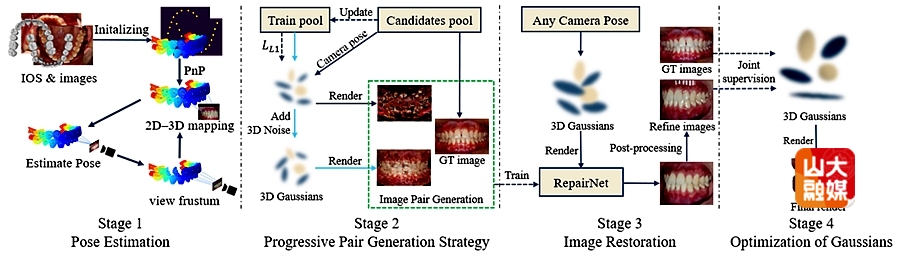
研究团队针对远程正畸中的牙齿可视化难题提出了全新的技术框架。正畸治疗监测通常依赖于诊检查,限制了远程医疗的发展。尽管3D高斯溅射(3DGS)能够生成真实的新视角图像,但在仅有五张无相机位姿、提示动态变化明显的口内图像条件下,仍面临几何结构不完整、视角不足及光照不一致等挑战。团队提出 DentalGS 框架解决上述挑战。该方法利用患者正畸前的口内扫描(IOS)数据作为先验,初始化带 ISO-FDI 牙齿类别标注的高斯点云,并在无位姿信息下通过迭代优化自动估计相机位姿。为缓解图像数量有限带来的几何和外观退化,研究者设计“渐进式配对生成策略”,构造“损伤–修复”图像对训练 RepairNet,以恢复退化细节。此外,团队提出“光照感知 3DGS”模块,基于物理反射特性减轻复杂光照对重建的影响。实验显示,该方法在极端视角下仍能保持结构完整,生成高质量新视角口内图像,为远程正畸监测提供高效可靠的3D可视化方案。软件学院博士研究生戴洪浩为该篇文章的第一作者,学院教授周元峰为通讯作者。
成果三:Benchmarking Multimodal Knowledge Conflict for Large Multimodal Models(oral)。

多模态大模型在处理多模态知识冲突时面临显著挑战,尤其是在检索增强生成框架下,当外部检索得到的上下文信息与模型内部参数化知识相矛盾时,容易导致输出结果不可靠。然而,现有的评测基准并未充分反映这种冲突场景。多数基准仅关注模型内部记忆冲突,而对上下文—记忆冲突及上下文间冲突的研究仍十分有限。此外,基于事实性知识的评估往往被忽视,现有数据集也缺乏对冲突检测能力的系统分析。为弥补这一空白,研究提出了MMKC-Bench,一个用于评估多模态事实性知识冲突的基准,涵盖了上下文—记忆冲突与上下文间冲突两种场景。MMKC-Bench包含三种类型的多模态知识冲突,共计1573条知识实例和3381张图像,分布于23个大类,通过自动化流程与人工核验相结合的方式构建而成。我们在模型行为分析与冲突检测两项任务上,对三类具有代表性的LMM系列进行了系统评测。实验结果表明,当前的LMM虽然具备一定的知识冲突识别能力,但往往倾向于信任其内部参数化知识,而忽视外部证据。研究希望MMKC-Bench能推动多模态知识冲突研究的发展,并促进多模态RAG系统的进一步完善。软件学院与C-FAIR副研究员杜云涛为该篇文章的通讯作者。
成果四:Aligning the True Semantics: Constrained Decoupling and Distribution Sampling for Cross-Modal Alignment。
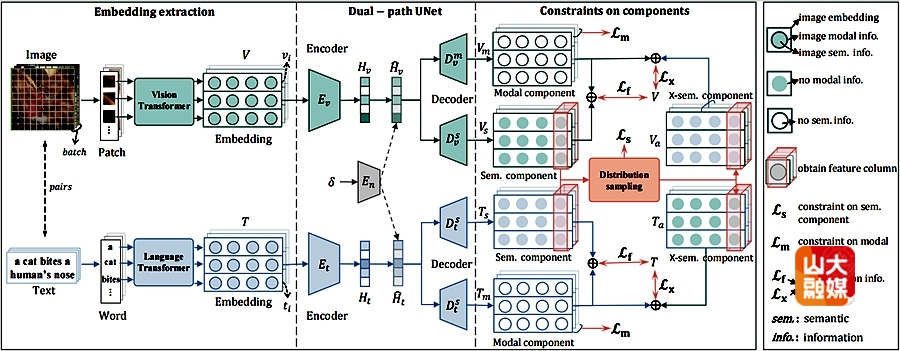
本研究主要针对跨模态对齐中的可靠性问题。跨模态对齐是多模态学习中的关键任务,旨在实现视觉与语言等不同模态之间的语义一致性,这要求图像-文本对展现出相似的语义特征。现有算法通过保证不同模态嵌入的一致性来实现语义对齐,却忽略了嵌入中存在的非语义信息,导致语义对齐偏差或信息损失。一种直观的解决思路是将嵌入解耦为语义成分与模态成分,仅对语义成分进行对齐。但语义信息与模态信息缺乏明确的区分标准,很难显示定义。为此,本研究提出一种通过带约束的解耦与分布采样(CDDS)的跨模态对齐新算法,核心包括:引入双路径UNet自适应解耦嵌入表示,通过多重约束确保有效分离;提出分布采样方法弥合模态差异,保障对齐过程的合理性。软件学院博士后马翔为该篇文章的第一作者,学院教授张彩明为通讯作者。
成果五:Ev-iCRF: Self-supervised Event-guided iCRF Estimation for HDR Image Reconstruction。
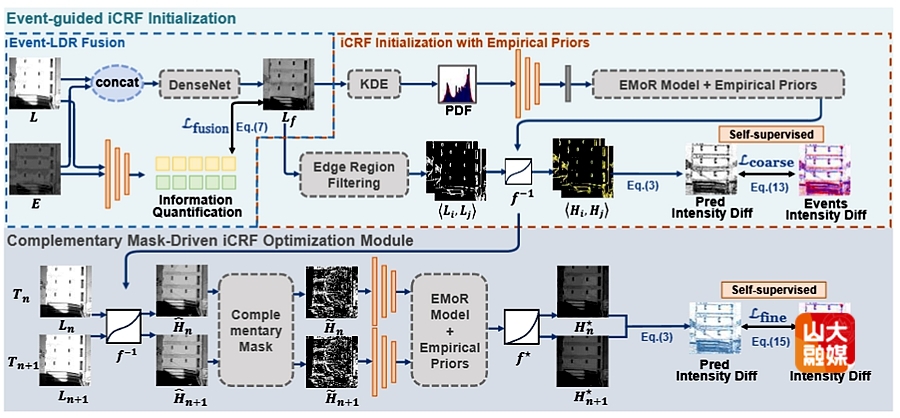
Ev-iCRF是一种利用仿生事件相机的异步事件流,进行单曝光低动态范围(LDR)图像高动态范围(HDR)重建的自监督学习方法。Ev-iCRF的核心创新在于基于事件-图像对应关系提出了逆相机响应函数(iCRF)的新型建模方式。借助事件数据所天然具备的高动态特性,该方法能够直接进行iCRF的估计,从而为事件驱动的HDR成像提供了全新的研究思路。在训练方式上,Ev-iCRF通过基于模型公式的iCRF估计损失和重建精炼损失实现自监督学习,无需同步的HDR监督数据即可完成端到端训练。系统采用两阶段粗到细的重建结构,有效融合LDR图像与事件数据的特征信息。事件信息被用于优化iCRF,使模型能够从单张LDR输入中准确重建HDR图像。在真实场景与合成数据集上的实验结果显示,Ev-iCRF在HDR重建精度方面显著优于现有最先进方法。同时,重建的图像在纹理保真度与结构细节方面也实现了明显提升。这一成果为事件相机在高动态成像领域的应用开辟了新的方向,并展示了事件视觉在自监督图像增强任务中的强大潜力。软件学院博士研究生郭旭城该篇文章的第一作者,学院教授沈益冉为通讯作者。
成果六:Multi-granularity Interactive Attention Framework for Residual Hierarchical Pronunciation Assessment 。
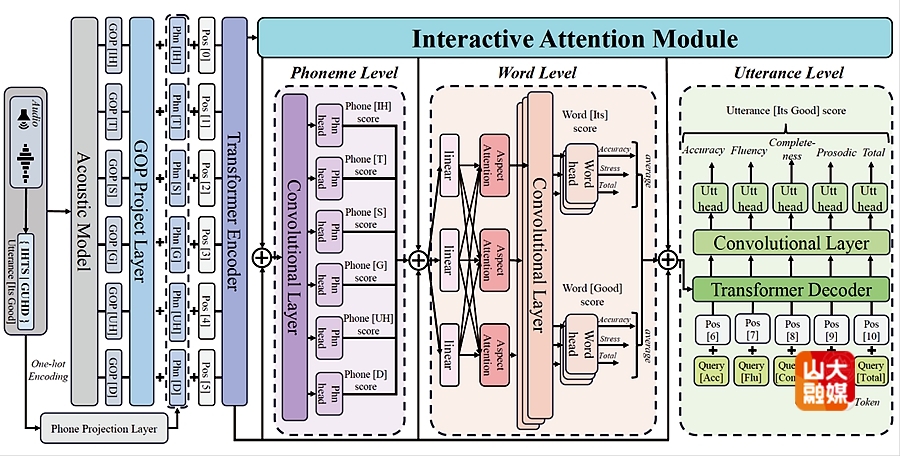
研究团队针对计算机辅助发音训练(CAPT)中的多维度评估难题提出了全新的技术框架。自动发音评估(APA)通常依赖于单层级建模,限制了复杂发音错误的诊断能力。尽管多粒度方法能并行处理音素、词汇与语句级任务,但在仅考虑相邻层级单向依赖、缺乏跨尺度双向交互的条件下,仍面临声学结构关联性缺失、特征遗忘及局部上下文提取不足等挑战。团队提出HIA框架解决上述挑战。该方法利用残差层次结构,初始化基于交互式注意力的跨粒度双向通路,并在无额外标注下通过注意力机制动态估计层级间依赖。为缓解单向交互带来的信息瓶颈,研究者设计“交互式注意力模块”,构造“音素–词汇–语句”三元组实现双向建模,以恢复丢失的声学关联。此外,团队使用“一维卷积增强”模块,基于局部感受野特性减轻特征遗忘对分层建模的影响。在speechocean762数据集上的实验显示,该方法取得显著超越现有最先进方法的综合性能,为非母语者英文发音训练提供高效可靠的多维度评估方案。软件学院硕士研究生韩鸿为该篇文章的第一作者,学院教授许信顺为通讯作者。
成果七:Explicit Modeling of Causal Factors and Confounders for Image Classification。
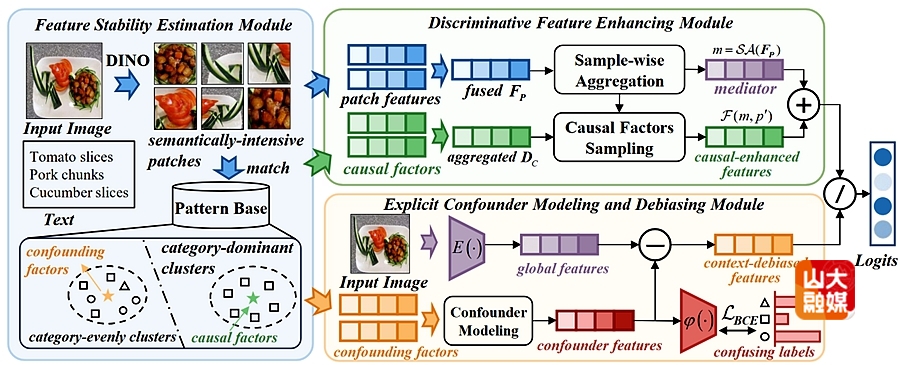
研究团队针对复杂场景下的图像分类易受语义混淆与虚假相关影响的问题,提出了新的因果表征学习框架 Explicit Modeling Causal Model(EMCM)。传统方法多依赖潜在混淆因素的隐式建模,偏向将偏差归结为背景信息,往往忽略目标级语义混淆,造成因果与混淆因素难以有效区分。EMCM 通过显式刻画因果因素与混淆因素,改善这一限制。首先,特征稳定性评估(FSE)模块利用语义聚类结构与标签信息,显式区分类别相关的因果因素和来自语义模糊类别的混淆因素。其次,因果特征增强(DFE)模块基于前门干预,将因果因素融入 patch 特征中,改善稳定语义表征。显式混淆建模与去偏(ECMD)模块在标签指导下直接学习混淆因素,并通过 TDE 建模生成去偏上下文特征。实验结果显示,EMCM 能在复杂场景下分离因果与混淆因素,并在多个数据集上获得优于现有因果去偏和文本引导方法的表现,为提升视觉表征的泛化能力提供了可行方案。软件学院硕士生吴畏为该篇文章的第一作者,孟雷教授为通讯作者。
成果八:Introducing Decomposed Causality With Spatiotemporal Object-Centric Representation For Video Classification。
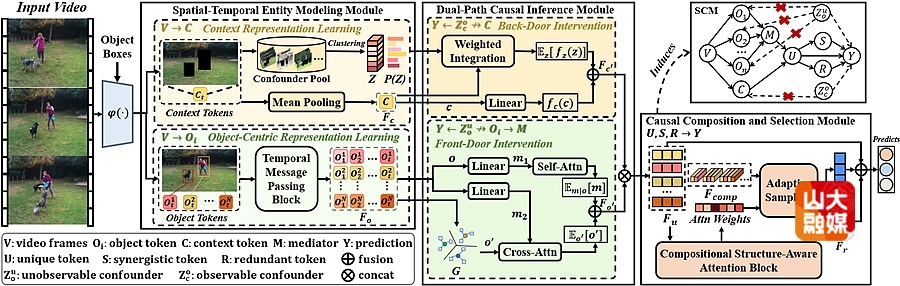
视频分类需要对对象及其交互进行事件级表示,而现有方法通常依赖数据驱动的方式,从整帧或对象中心的视觉区域中学习特征,因此往往忽略了对象间的时空交互。为此,本文提出了一种协同、独特与冗余因果表示分解学习(SurdCRL)模型,该模型引入 SURD 因果理论,用于建模对象动态及其帧内与跨帧交互的时空特征。具体而言,SurdCRL 通过三个模块对对象中心的时空动态进行建模:时空实体建模模块将帧解耦为对象与上下文实体,并利用时序消息传递捕捉对象状态随时间的变化,生成基本因果变量;双路径因果推理模块通过前门和后门干预缓解因果变量间的混淆因素,使后续因果成分能够反映其内在效应;因果组合与选择模块利用结构感知组合注意力,将因果变量及其高阶交互映射为协同、独特和冗余三类因果成分。在两个基准数据集上的实验结果表明,SurdCRL 通过分解时空对象交互,更有效地捕捉了与事件相关的对象中心表示。软件学院硕士研究生张亚冲为该篇文章的第一作者,孟雷教授为通讯作者。
成果九:Retriever Encoder Selection Matters for In-Context Learning-based Medical Segmentation 。
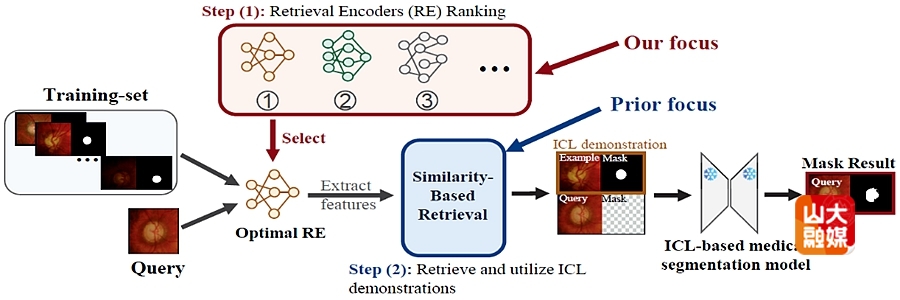
研究团队针对医学影像分割中基础模型泛化受限的问题,提出了基于上下文学习的实例自适应检索编码器选择框架(IRES)。传统方法依赖固定的检索编码器(RE)将查询样本与训练样本映射到共享特征空间,但团队发现,RE的选择本身可造成超过70%的性能差异,是影响模型效果的关键因素。为此,研究者提出 IRES方法,通过输出预测结果动态选择最优编码器,从而针对每个查询自适应地提升分割性能。其核心指标为形状稳定性评分,用于评估预测掩膜在迭代腐蚀下的形态稳定性,实验表明该指标与真实编码器质量高度相关。此外,团队设计了并行预测与互惠邻居复用机制,显著降低推理开销。实验结果显示,IRES 在FUNDUS、Brain MRI 与 Chest X-ray 等数据集上均取得显著性能提升,为医学影像分割中的动态模型选择提供了高效可靠的新方案。软件学院博士研究生王帆为该篇文章的第一作者,学院教授尹义龙、韩忠义为共同通讯作者。
成果十:MTRL-CG: Multi-Task Reinforcement Learning with Spectral Clustering-Based Task Grouping。
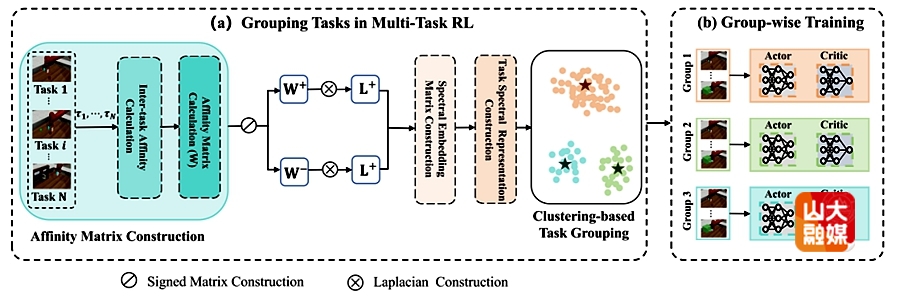
该研究针对多任务强化学习(Multi-Task Reinforcement Learning, MTRL)中任务间干扰与负迁移问题,提出了全新的MTRL-CG框架。现有多任务强化学习方法通常采用完全共享的策略网络,在面对任务间差异或冲突时,容易出现梯度相互抵消、性能下降等现象,限制了其在复杂环境中的应用。该研究提出的MTRL-CG方法从任务间的相互影响出发,首次在多任务强化学习中引入任务分组机制。团队首先通过评估一个任务在共享函数上的梯度更新对其他任务Q值的影响程度来衡量任务间亲和力(Affinity),从而构建任务间亲和度矩阵。在此矩阵基础上,为得到有效分组,研究者采用符号谱聚类,构建任务谱表示并应用k-means聚类形成最终的分组。最后,团队根据分组结果分别在每个任务组内独立训练强化学习模型。每个任务组分配一个专用的SAC模型,以实现集中的策略学习,促进组内知识共享,同时减少不相关任务的干扰。实验显示,该方法能够在多种仿真环境中显著提升准确率和稳定性,为多任务强化学习的高效学习与泛化提供了新的解决方案。软件学院助理研究员孟文佳为该篇文章的第一作者。
成果十一:PEOCH: Online Cross-Modal Hashing With Semi-supervised Streaming Data Driving Prototype Evolution 。
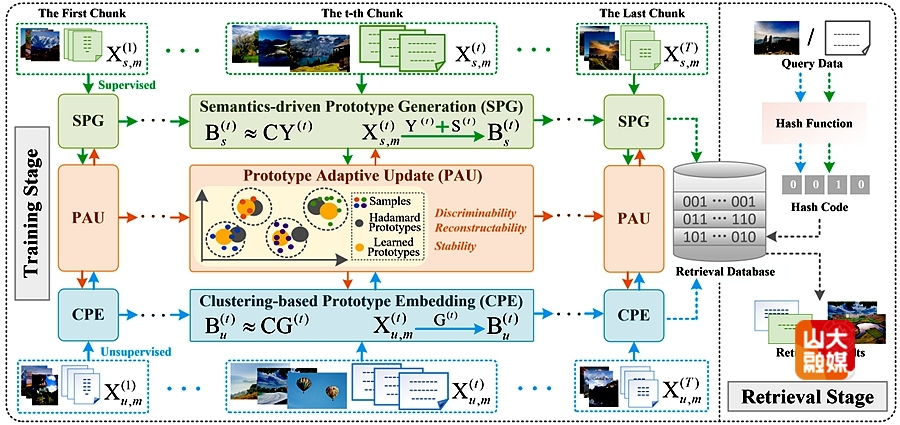
研究团队针对流媒体多模态数据爆发式增长带来的三大挑战——数据分布漂移、模态鸿沟及标注稀缺,提出了基于原型演化的在线跨模态哈希方法PEOCH。现有半监督在线哈希方法难以生成高质量的无监督哈希码,从根本上限制了检索过程的多样性与灵活性。为此,研究者设计了一种通过半监督流数据驱动原型演化的新型框架,能够为标注与未标注数据同时生成精准稳定的哈希码。其核心机制在于双原型协同更新:标注样本将语义知识推入原型,而未标注样本通过原型牵引指导哈希码生成。团队设计了协同优化架构,确保原型能够基于整体流数据持续演化,同时引入融合判别性与平滑性约束的弹性正则器,显著提升原型可靠性。研究还提供了严格的理论证明,确保原型更新过程的稳定性。实验结果表明,PEOCH在三个标准数据集上全面优于现有最优方法,在多类检索任务中平均mAP@all指标提升达6.7%,为流式跨模态检索提供了兼具理论保证与实用价值的创新解决方案。软件学院博士后康潇为该篇文章的第一作者。
成果十二:Decompose and Conquer: Compositional Reasoning for Zero-Shot Temporal Action Localization。
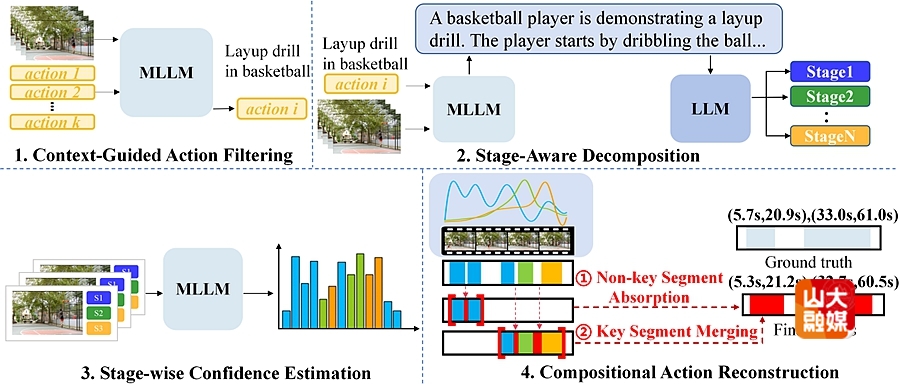
零样本时序动作定位 (Zero-Shot Temporal Action Localization, ZSTAL) 作为开放世界视频理解领域的一项核心挑战任务,旨在定位视频中未曾出现在训练集中的动作实例。然而,当前的ZSTAL方法,无论是基于训练还是免训练的,通常都依赖于单一的、统一的查询来定位整个动作。这种统一的表示在面对以内部组合结构、动态性和多阶段变化为主导的复杂现实世界活动时,存在根本性缺陷,无法捕获活动的内部组合结构,也难以适应视频中动态的、多阶段的变化。为此,本研究提出了一种新颖的组合推理框架CASCADE(Context-Aware Staged Action DEcomposition)。该框架的灵感来源于人类认知过程中的“感知上下文、分解事件和重建实例”步骤,并遵循一个免训练的流程,实现轻量化且鲁棒的定位。该框架利用多模态大语言模型 (MLLM) 感知视频的上下文,通过过滤不相关动作并为每个现有动作生成丰富的、视频特定的描述,从而紧凑地捕捉稳定的上下文规律。为弥补统一查询过程中未保留的阶段性变化,CASCADE 采用一种分解-重建架构:首先将动作分解为具有清晰语义的阶段性子动作,并为每个子动作生成多个细粒度的查询;随后,通过一个新颖的内容感知的相似度聚合机制,CASCADE将这些子动作的定位结果重建为一个完整的动作实例。两个公开数据集上的实验结果表明,CASCADE显著优于现有的ZSTAL方法,有力地证明了将ZSTAL视作组合推理任务的有效性。软件学院助理研究员唐昊煜为该篇文章的第一作者,学院副研究员胡宇鹏为通讯作者。
成果十三:ReTrack: Evidence-Driven Dual-Stream Directional Anchor Calibration Network for Composed Video Retrieva。
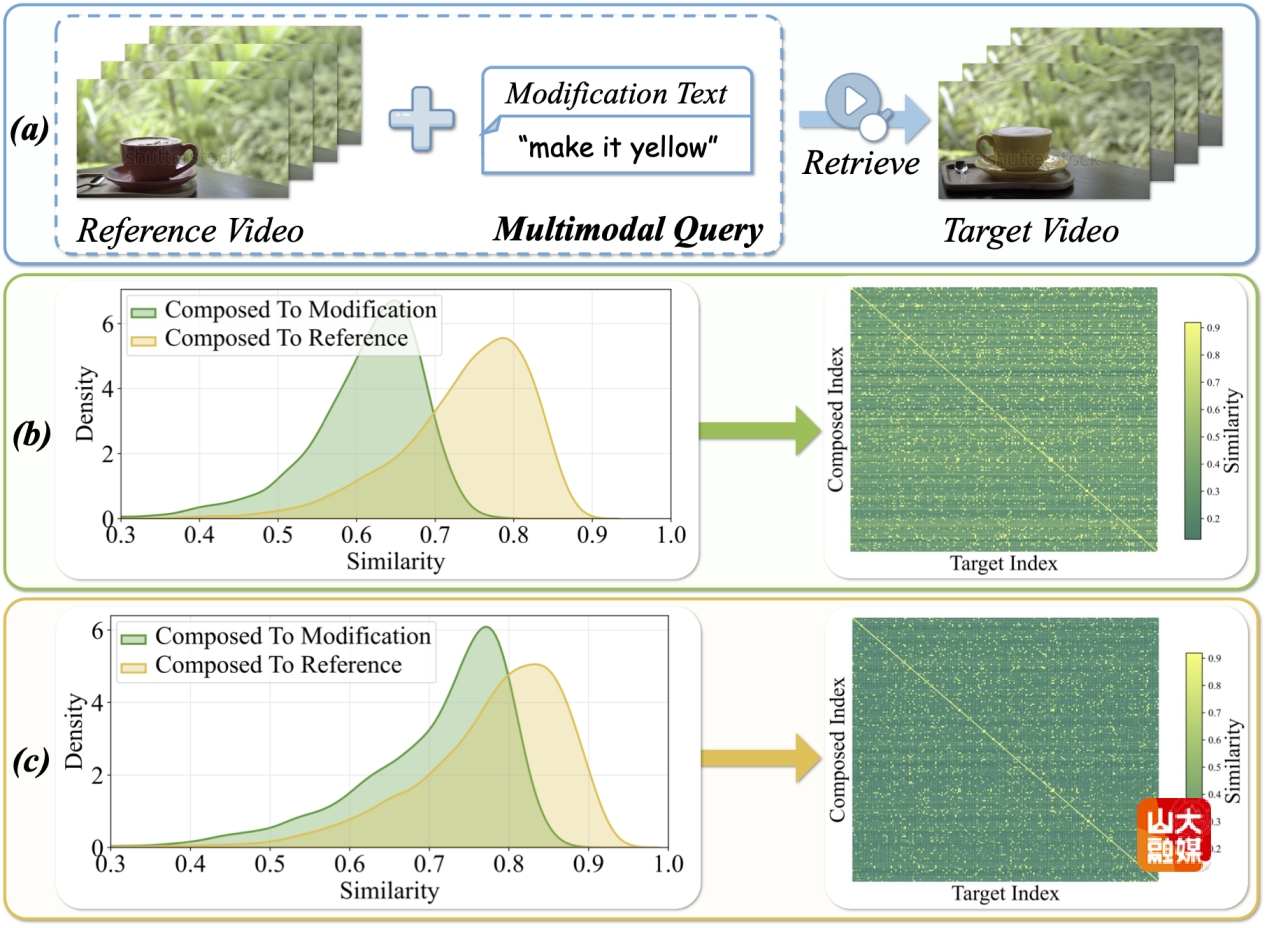
随着视频数据的快速增长,组合视频检索(Composed Video Retrieval, CVR)作为一种新颖的视频检索范式,正受到越来越多研究者的关注。与单模态视频检索方法不同,CVR 任务的输入是一个多模态查询(包括参考视频和一段修改文本),其中修改文本用于表达用户希望在参考视频基础上进行的修改需求。随后,模型根据这一输入检索最相关的目标视频。在CVR任务中,视频与文本在信息密度上存在显著差异,传统的组合方式容易使组合特征过度偏向参考视频,从而导致次优的检索结果。由于以下三个挑战,这一局限性并非微不足道:1)模态贡献耦合;2)组合特征的显式优化;3)检索不确定性。为了解决上述挑战,研究提出了基于证据驱动的双流方向锚点校准网络(ReTrack)。ReTrack 是第一个通过纠正组合特征方向偏差来提升多模态查询理解能力的 CVR 框架,它包括三个关键模块:(a) 模态语义贡献解耦;(b) 组合几何校准;(c) 可靠的证据驱动对齐。通过估计各模态的语义贡献来校准组合特征中的方向偏差,并基于校准后的方向锚点计算双向证据,从而驱动更可靠的组合查询与目标视频相似度计算。此外,研究提出的ReTrack还能够同时适用于组合图像检索(CIR)任务,并在四个CVR与CIR基准数据集上均取得了当前最先进的性能。软件学院博士研究生李子旭为该篇文章的第一作者,胡宇鹏副研究员为通讯作者。
成果十四:INTENT: Invariance and Discrimination-aware Noise Mitigation for Robust Composed Image Retrieval。
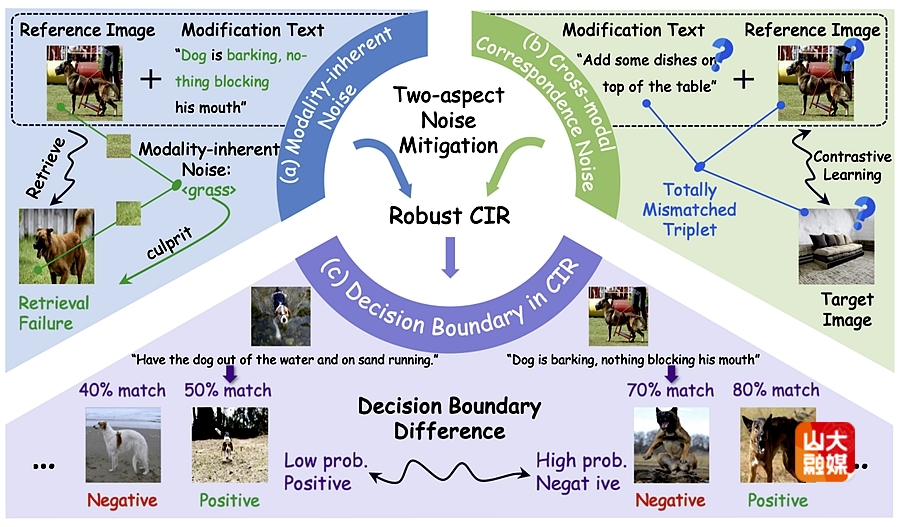
组合图像检索(Composed Image Retrieval, CIR)是一种具有挑战性的图像检索范式,它允许用户通过一组多模态查询(包含一张参考图像和一条修改文本)来检索目标图像。尽管过去几年该任务取得了显著进展,但这些方法大多建立在一个前提假设之上——即所有样本都是正确匹配的。然而在实际应用中,由于三元组标注成本高昂,CIR数据集中往往不可避免地存在错误标注,即匹配关系不正确的三元组。为了解决这一问题,噪声三元组对应(Noisy Triplet Correspondence, NTC)开始受到研究者的关注。研究认为,CIR任务中的噪声可以分为两类:跨模态对应噪声和模态固有噪声。前者来源于模态间的错误匹配,后者则来源于模态内部的干扰背景,或那些与粗粒度修改标注无关的视觉因素。然而,现有研究始终忽略了后者。为此,研究提出了一种具有“不变性与判别性感知”的噪声网络(INTENT),其由两部分组成:面向固有噪声的视觉不变表征和双目标判别式学习。前者通过快速傅里叶变换(FFT)在频域施加扰动以生成干预样本,在破坏高频无关模式的同时保留低频语义结构,从而排除原生噪声干扰;后者则基于多粒度置信度估计来计算样本匹配忠诚度,软化决策边界,从而实现鲁棒的组合对齐学习。在两个广泛使用的基准数据集上进行的大量实验证明了INTENT的优越性和鲁棒性。软件学院硕士研究生陈智伟为该篇文章的第一作者,胡宇鹏副研究员为通讯作者。
成果十五:HABIT: Chrono-Synergia Robust Progressive Learning Framework for Composed Image Retrieval。
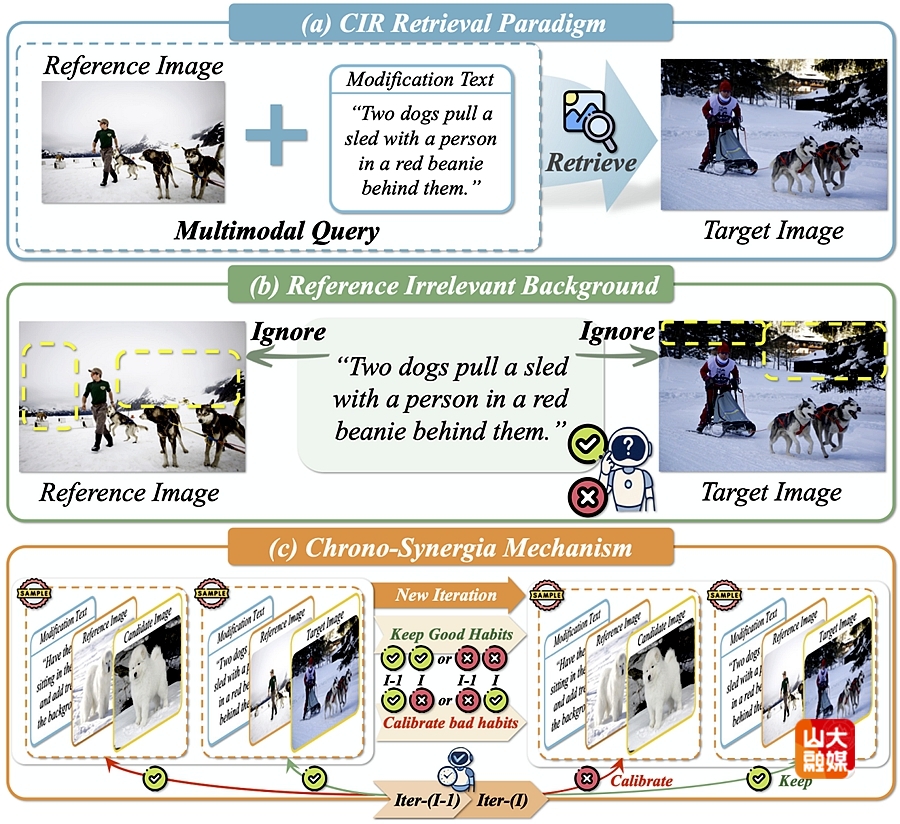
组合图像检索(Composed Image Retrieval, CIR)是一种灵活的图像检索范式,允许用户通过由参考图像与修改文本组成的多模态查询来精准获取目标图像。尽管该任务在个性化搜索与推荐系统中具有广泛的应用前景,但由于三元组数据标注成本高且具有较强主观性,在实际应用中往往面临严重的噪声三元组对应问题(Noisy Triplet Correspondence, NTC)。为了解决这一问题,我们主要需要应对两个挑战:其一是对组合语义差异进行精细估计,其二是如何缓解由修改差异带来的渐进适应性不足。针对上述挑战,我们提出了一种用于组合图像检索的时间协同稳健渐进学习框架(HABIT)。HABIT包含两个关键模块:互知识评估模块,通过计算组合特征与目标图像之间的互信息变化率来量化样本的“干净”程度,从而有效识别符合修改语义的干净样本;双知识一致性渐进学习模块,该模块引入历史模型与当前模型的协同机制,模拟人类习惯养成过程,保留“好习惯”、纠正“坏习惯”,以实现模型在噪声三元组环境中的鲁棒学习。在两个标准 CIR 数据集上的大量实验结果表明,HABIT在多种噪声比例下均显著优于现有最先进方法,展现出更强的噪声鲁棒性与检索性能。软件学院博士研究生李子旭为该篇文章的第一作者,胡宇鹏副研究员为通讯作者。
成果十六:DHMRec: Collaboration-Guided Multimodal Disentanglement and Hierarchical Fusion for Recommendation。
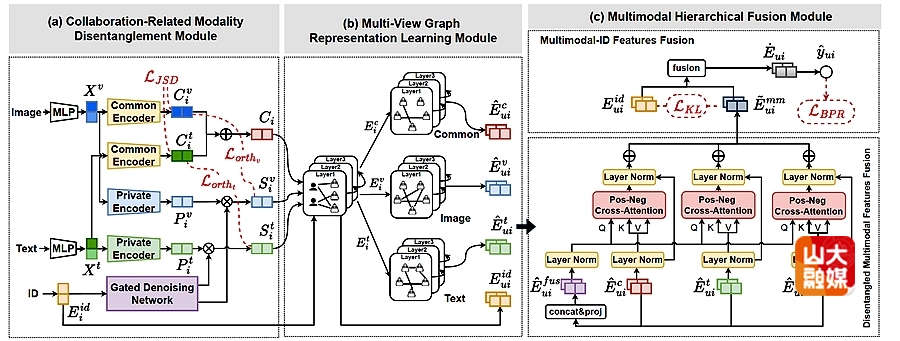
多模态推荐系统已成为利用多种数据模态提供个性化服务的关键范式。当前的研究主要集中在通过图学习整合异构模态信息。然而,这些方法面临两个关键挑战:(1)模态固有的复杂性,表现为纠缠的冗余信号和噪声;(2)有效整合多模态表示的挑战,不同模态表示可能对用户的偏好产生不同程度的影响。为了解决这些挑战,我们提出了一种新颖的协作引导多模态解耦与分层融合推荐方法(DHMRec),该方法同时实现了模态内的去噪解耦和模态间的分层融合。具体而言,我们引入了一个与协作相关的模态解耦模块,以区分模态共有的特征和模态特有的特征。然后,通过多视图图学习来捕获项目间依赖关系和用户-项目交互模式。此外,我们还在解耦的多模态特征和ID嵌入之间实现了分层融合,分别采用基于正负注意力感知的融合模块和基于交互分布的对齐模块。在三个基准数据集上进行的大量实验表明,我们提出的DHMRec优于基线模型,突显了其在模态内解耦和多模态特征融合方面的有效性。软件学院硕士研究生展小涵为该篇文章的第一作者。学院教授史玉良,王继虎为共同通讯作者。
AAAI人工智能会议(AAAI Conference on Artificial Intelligence)是人工智能领域最具有影响力的国际顶级学术会议之一,被中国计算机学会(CCF)列为A类会议。本届会议共受到23680篇有效投稿,共录用4167篇文章,录用率约为17.6%,为近四年最低。

















