[本站讯]近日,控制科学与工程学院姬冰教授团队在医学影像领域顶级期刊IEEE Transactions on Medical Imaging(中科院一区TOP,IF=9.8)在线发表题为“EviVLM: When Evidential Learning Meets Vision Language Model for Medical Image Segmentation”的研究论文。山东大学硕士研究生潘庆涛为论文第一作者,姬冰教授为论文通讯作者,山东大学为论文第一完成单位。
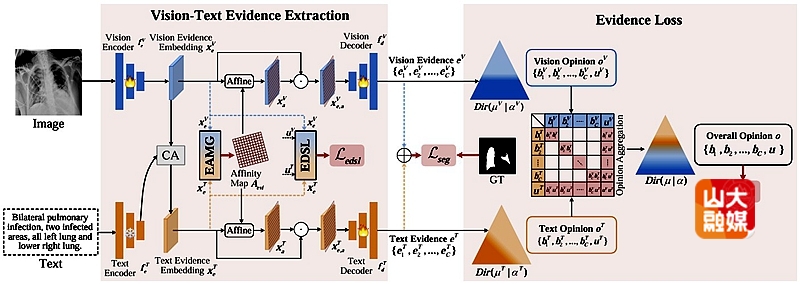
图像和文本表示之间的差异,通常被称为语义鸿沟,是医学视觉语言模型(Medical Vision Language Model)中的一个重要问题。这种差异导致医学图像和文本间的融合变得复杂,从而限制了医学视觉语言模型在医学图像分割任务中的性能。当前主流的医学视觉语言模型主要通过对齐损失将这些特征嵌入到共享空间中,尽管如此,其不足以缓解语义鸿沟,因为共享空间的窄锥分布加剧了模态间的语义不均衡,限制了模型对跨模态语义一致性的建模能力。
为了解决上述难题,该研究提出了证据学习驱动的视觉语言模型(Evidential Learning driven Vision Language Model)。该研究使用主观逻辑理论将图像文本特征转换为证据向量(Evidence),进而基于证据向量构建狄利克雷分布,把证据向量映射为意见向量(Opinion)。最后引入基于Dempster-Shafer理论的组合规则进行意见聚合,从而量化语义鸿沟,实现高效地的多模态融合。在三个代表性数据集上的实验结果表明,所提出方法的性能优于当前的传统医学图像分割方法以及视觉语言模型引导的医学图像分割方法。
姬冰教授团队长期致力于医工融合领域研究工作,聚焦于基于人工智能方法开展疾病的精准诊疗,相关研究成果发表在IEEE Transactions on Medical Imaging、Information Fusion、Artificial Intelligence Review、AAAI、MICCAI等学术期刊和顶级会议。该研究获得国家自然科学基金、山东省泰山学者青年专家等项目的资助。山东大学智能医学工程研究中心为本研究提供了平台支持。

















