[本站讯]近日,计算机科学与技术学院师生撰写的4篇论文被SIGIR 2023录用,3篇为full paper,1篇为resource paper。计算机学院在联邦学习推荐系统、推荐系统中多行为建模、基于强化学习的推荐系统以及对话式推荐系统上所作的工作获得国际审稿专家的高度评价。所录用的文章第一完成单位均为山东大学。
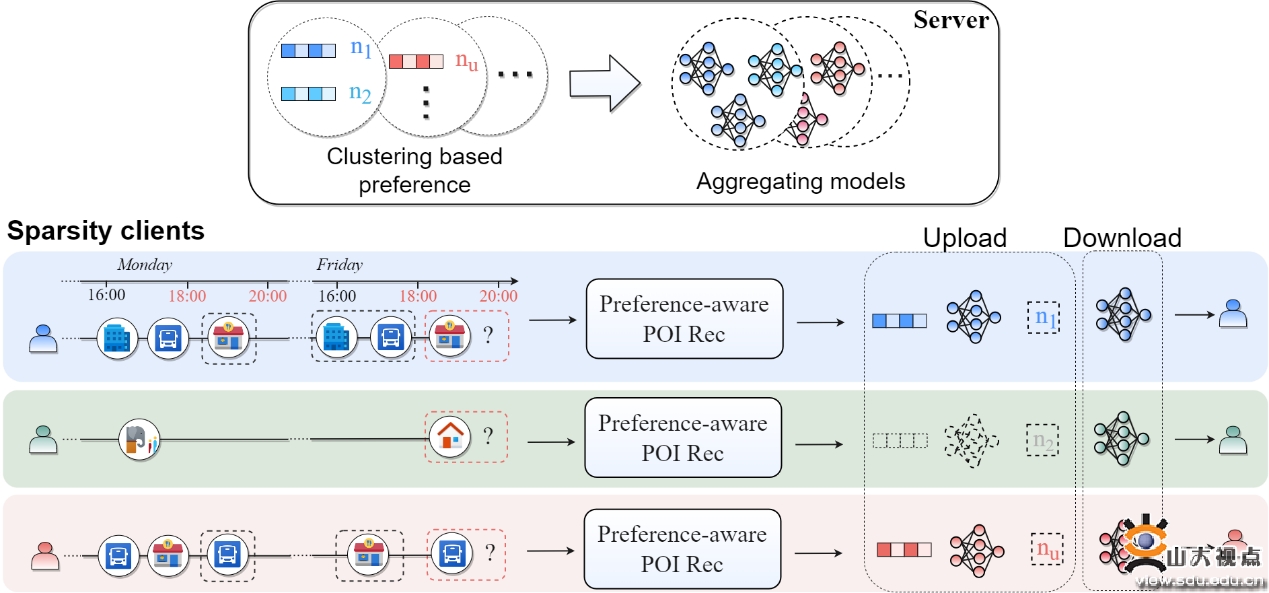
图1:所提方法的整体框架
第1篇长文标题为“Fine-Grained Preference-Aware Personalized Federated POI Recommendation with Data Sparsity”,研究主题是个性化的联邦学习推荐系统(图1)。随着人们对隐私问题的逐渐重视和数据监管的日益严格,联邦学习已成为推荐领域热门的协作学习范式,被用于在不共享敏感数据的前提下进行POI推荐。然而现有方法中仍存在着许多挑战:(1)用户的偏好具有高度的时间敏感性;(2)用户之间的偏好是高度异质的;(3)用户的数据是高度稀疏的。为了解决上述问题,本文设计了一个基于细粒度用户偏好的个性化联邦POI推荐框架PrefFedPOI。具体而言,在客户端方面,本文提出了一个细粒度偏好推荐模型,通过结合最近访问偏好和周期访问偏好来提取当前时间窗口的用户偏好。其后,为了解决数据稀疏的问题,本文提出了一个基于强化学习的自适应聚类机制,以基于用户偏好的内在相似性增强用户间有效知识的共享。此外,为了确保聚类的高效性,本文设计了一个聚类教师网络用以加速引导网络聚类的训练进程。本文在两个不同的真实数据集上进行了广泛的实验,实验结果表明了所提方法的有效性。本文由学院教授于东晓和助理教授张啸共同指导,第二作者是硕士研究生叶梓铭。合作教师包括武汉理工大学研究员鲁建峰、北京航空航天大学研究员庄福振、山东大学副教授郑艳伟。
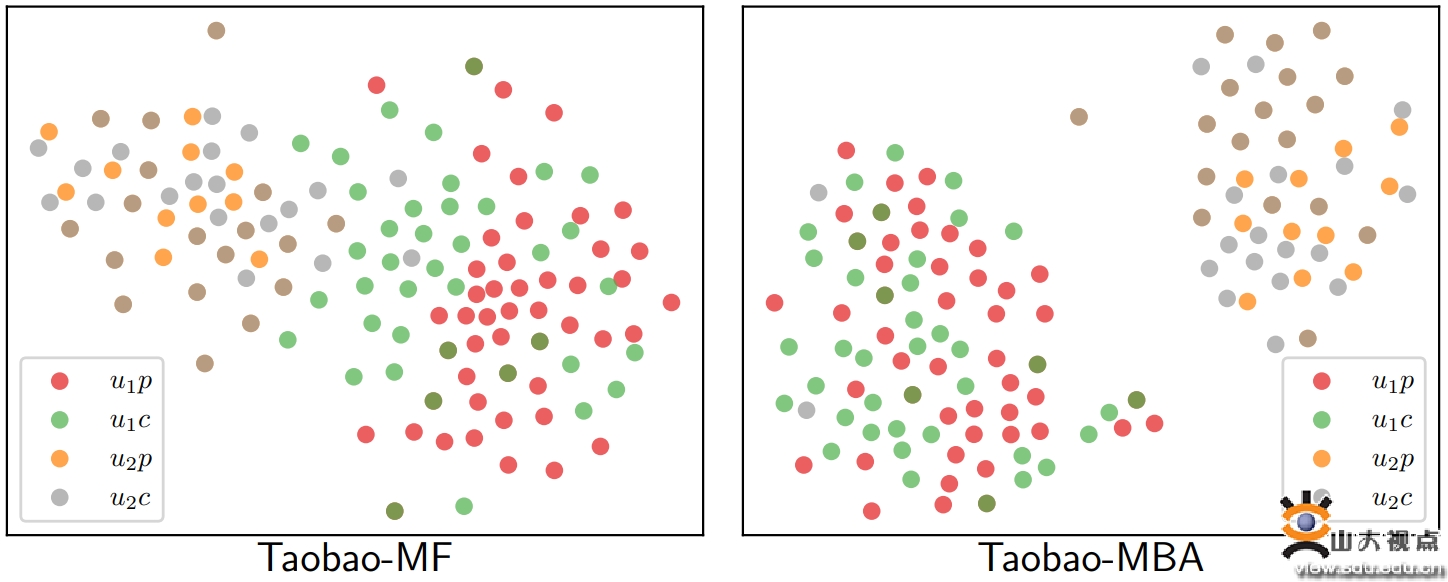
图2:在淘宝数据集中两个不同用户在MF和MBA中点击和购买行为的分布情况。红点代表用户1的购买行为分布,绿点代表用户1的点击行为分布,黄点代表用户2的购买行为分布,灰点代表用户2的点击行为分布。本文提出的MBA可以对齐用户多行为分布,并推断出普遍且准确的用户偏好,同时提供比MF更个性化的用户特定推荐服务。
第2篇长文关注推荐系统中用户多种行为(图2),题目为“Improving Implicit Feedback-Based Recommendation through Multi-Behavior Alignment”。基于隐式反馈学习的推荐系统通常使用大量单一类型的隐式用户反馈(如点击)来增强对稀疏目标行为(如购买)的预测。如何将多种类型的隐式用户反馈用于此类目标行为预测中是当前所面临的一个研究问题。现有的利用多种用户行为类型进行学习的相关工作中往往无法:(1)从不同的行为数据分布中学习到普遍和准确的用户偏好;(2)克服观察到的隐式用户反馈中的噪声和偏差。为了解决上述问题,本文提出了一个基于多行为对齐的学习框架MBA,通过使用多种类型的行为数据来增强从隐式反馈中学习的推荐系统。本文推测来自同一用户的多种类型的行为(如点击和购买)应该反映该用户的相似偏好。为此,本文将潜在的普遍用户偏好视为隐变量。该隐变量通过最大化多个观察到的行为数据分布间的似然度的同时,最小化从辅助行为(如点击或查看)和目标行为(如购买)中分别学习到的用户模型之间的KL-散度来推断得到。MBA从多行为数据中推断出普遍的用户偏好,执行数据去噪的同时实现有效的知识迁移。本文在两个公开数据集和美团数据集上进行了实验,实验表明了提出方法的有效性。本文由学院教授任昭春和助理教授辛鑫共同指导,主要完成者包括硕士研究生刘祥源和本科生王涵冰,参与指导教师有学院研究员任鹏杰、陈竹敏教授。本文合作方包括美团推荐团队,格拉斯哥大学教授Joemon Jose、阿姆斯特丹大学教授Maarten de Rijke。
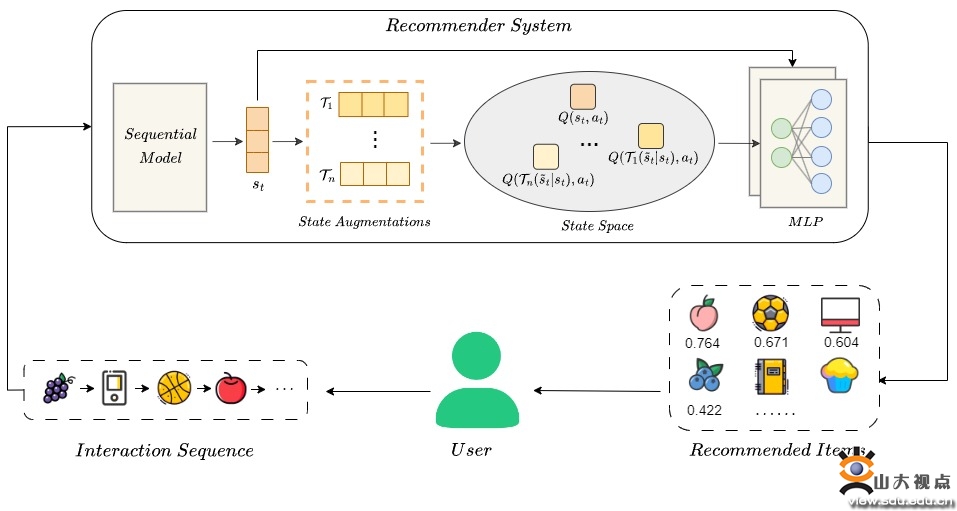
图3:对比状态增强方法。对于user-item历史交互序列,通过序列模型获得状态表示后进行状态增广,从而扩大了离线数据的状态空间。
第3篇长文为“Contrastive State Augmentations for Reinforcement Learning-Based Recommender Systems”,其探索强化学习中的状态增广(图3)。从user-item历史交互序列中训练基于强化学习的推荐系统对于生成高质量的推荐和提高长期累积收益至关重要。然而,现存的基于强化学习的方法对于估计离线训练数据中不包含的状态的值函数仍有困难。同时,由于缺乏对比信号,从用户的隐式反馈中也很难学习到有效的状态表示。在这篇工作中 ,本文提出了对比状态增强(CSA)的方法来训练基于强化学习的推荐系统。为了解决上述第一个问题,作者提出了4种状态增强的策略来扩大离线数据的状态空间。该方法通过使用RL代理访问局部状态区域,确保学习到的值函数在原始状态和增广状态之间是相似的,从而提升推荐系统的泛化能力。对于第二个问题,作者建议在增广状态和随机采样于其他会话的状态之间引入对比信号,以进一步提高状态表示学习。为了证明本文提出的CSA方法的有效性,本文在两个公开的数据集和美团数据集上进行充分的实验。本文还在一个模拟环境上进行了实验,作为在线评估设置。实验结果证明了CSA能够有效提升推荐性能。本文由学院教授任昭春、助理教授辛鑫共同指导,主要完成者包括硕士研究生黄娜、王一丹,参与指导教师包括任鹏杰研究员、教授马军。本文合作方包括美团推荐团队和Joemon Jose教授。

图4:E-ReDial数据集的一个片段,对于每个系统的回复包含其对应的知识,对话与知识的不同部分由不同的颜色高亮。
第4篇工作为resource track paper,“Towards Explainable Conversational Recommender Systems”,其关注对话式推荐的评估问题(图4)。传统的推荐系统中的解释可以帮助用户理解推荐的合理性,提高系统的效率、透明度和可信度。在对话环境中,多个符合语境的解释需要被生成,这给解释带来了更多的挑战。为了更好地衡量对话推荐系统(CRS)的可解释性,作者基于传统推荐系统的概念和CRS的特点提出了十个评价视角。本文使用这些指标评估了五个现有的CRS基准数据集,并观察到了提高CRS解释质量的必要性。为了实现这一目标,本文采用了人工和自动两种方法来扩展这些对话,并构建了一个新的CRS数据集——可解释的推荐对话数据集(E-ReDial)。本文比较了两种基于E-ReDial进行解释生成的基线方法,实验结果表明,在E-ReDial上训练的模型可以显著提高可解释性,而在模型中引入知识可以进一步提高性能。GPT-3在上下文学习设置中可以生成更真实和多样化的电影描述,相比之下,T5在E-ReDial上训练可以更好地根据用户偏好生成清晰的推荐理由。本文由任昭春教授指导,主要完成者包括博士研究生郭书宇、硕士研究生孙维纬,合作导师为Bloomberg张硕,任鹏杰研究员和陈竹敏教授参与指导。
SIGIR,全称为国际计算机协会信息检索大会(ACM International Conference on Research and Development in Information Retrieval),是人工智能领域智能信息检索方向最权威的国际会议,也是中国计算机学会CCF推荐的A类会议。涵盖了与信息检索相关的广泛主题,包括搜索算法和模型、自然语言处理、机器学习、人机交互、网络搜索、多媒体检索、推荐系统等。本届大会共收到822篇长文投稿,仅有165篇长文被录用,录用率约20.1%。

















